

4·
3 months agoIf you are talking about Lasagne - the pasta type and not the finished product, you would be right in saying you can find it both with eggs and without, by the article it says it is a north/south thing in Italy. But honestly you can find thousands of variations of them even moving just a few dozens kilometer.
On the contrary to be spaghetti and not something else they need to be - to directly quote - “a special pasta format made exclusively from durum wheat semolina and water, with a long, thin shape and round cross section.”
I’m not sure if it is the same outside of Italy. But at the end just do what makes you happy.








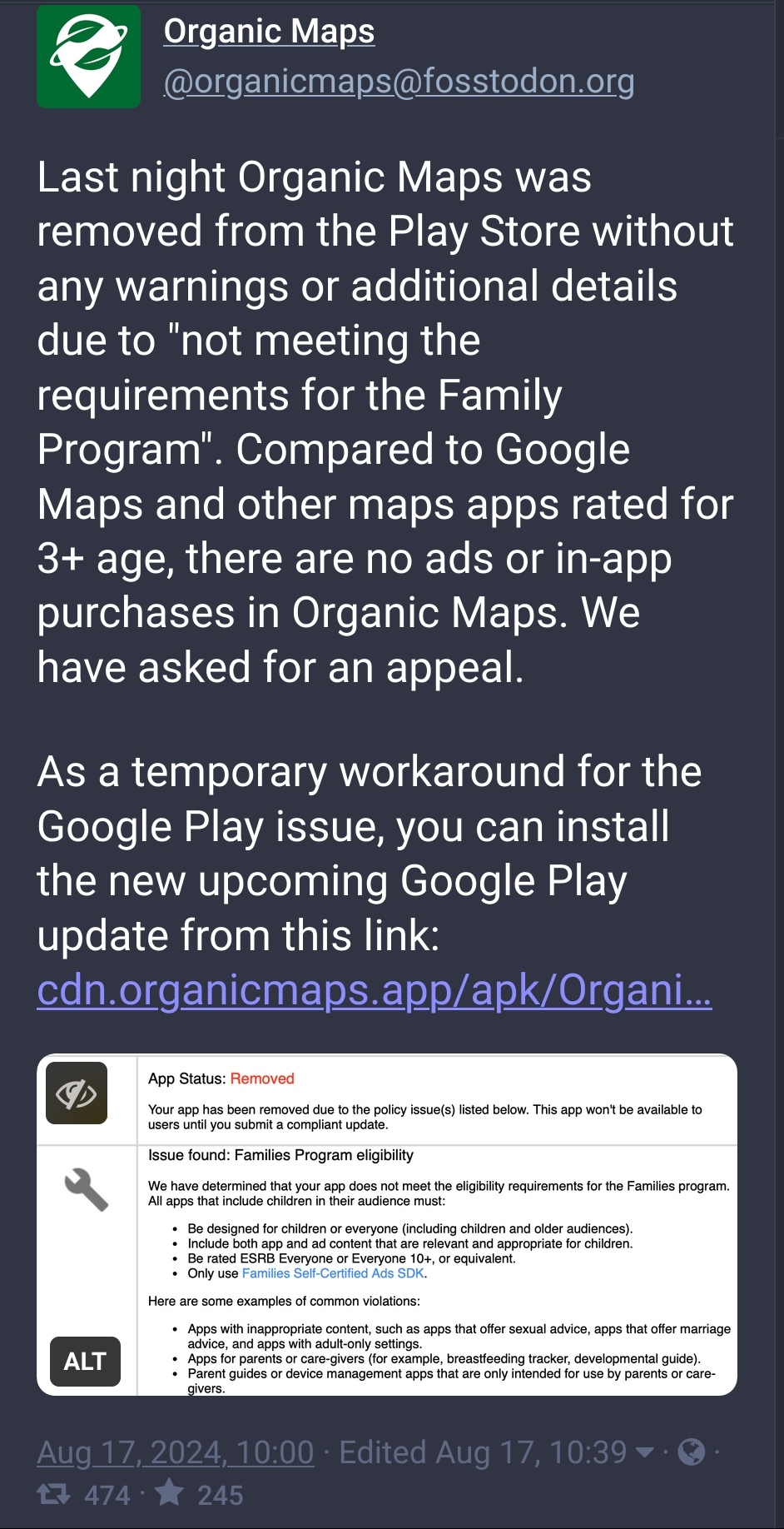{kind=link}
That’s the bad thing about social media. If no one was doing it before, someone is now!
Jokes aside it’s possible, but with the current LLMs I don’t think there’s really a need for something like that.
Malicious actors usually try to spend the least amount of effort possibile for generalized attacks, because you end up having to often restart when found out.
So they probably just feed an LLM with some examples to get the tone right and prompt it in a way that suits their uses.
You can generate thousands of posts while Lemmy hasn’t even started to reply to one.
If you instead want to know if anyone is taking all the comments on lemmy to feed to some model training… Yeah, of course they are. Federation makes it incredibly easy to do.