
1·
1 day agoAh, I see - this is effectively the same as the first image I shared, but via shell instead of GUI, right?
For my NFS server CT, my config file is as follows currently, with bind-mounts:
arch: amd64
cores: 2
hostname: bridge
memory: 512
mp0: /spynet/NVR,mp=/mnt/NVR,replicate=0,shared=1
mp1: /holocron/Documents,mp=/mnt/Documents,replicate=0,shared=1
mp2: /holocron/Media,mp=/mnt/Media,replicate=0,shared=1
mp3: /holocron/Syncthing,mp=/mnt/Syncthing,replicate=0,shared=1
net0: name=eth0,bridge=vmbr0,firewall=1,gw=192.168.0.1,hwaddr=BC:24:11:62:C2:13,ip=192.168.0.82/24,type=veth
onboot: 1
ostype: debian
rootfs: ctdata:subvol-101-disk-0,size=8G
startup: order=2
swap: 512
lxc.apparmor.profile: unconfined
lxc.cgroup2.devices.allow: a
lxc.cap.drop:
For full context, my list of ZFS pools (yes, I’m a Star Wars nerd):
NAME USED AVAIL REFER MOUNTPOINT
holocron 13.1T 7.89T 163K /holocron
holocron/Documents 63.7G 7.89T 52.0G /holocron/Documents
holocron/Media 12.8T 7.89T 12.8T /holocron/Media
holocron/Syncthing 281G 7.89T 153G /holocron/Syncthing
rpool 13.0G 202G 104K /rpool
rpool/ROOT 12.9G 202G 96K /rpool/ROOT
rpool/ROOT/pve-1 12.9G 202G 12.9G /
rpool/data 96K 202G 96K /rpool/data
rpool/var-lib-vz 104K 202G 104K /var/lib/vz
spynet 1.46T 2.05T 96K /spynet
spynet/NVR 1.46T 2.05T 1.46T /spynet/NVR
virtualizing 1.20T 574G 112K /virtualizing
virtualizing/ISOs 620M 574G 620M /virtualizing/ISOs
virtualizing/backup 263G 574G 263G /virtualizing/backup
virtualizing/ctdata 1.71G 574G 104K /virtualizing/ctdata
virtualizing/ctdata/subvol-100-disk-0 1.32G 6.68G 1.32G /virtualizing/ctdata/subvol-100-disk-0
virtualizing/ctdata/subvol-101-disk-0 401M 7.61G 401M /virtualizing/ctdata/subvol-101-disk-0
virtualizing/templates 120M 574G 120M /virtualizing/templates
virtualizing/vmdata 958G 574G 96K /virtualizing/vmdata
virtualizing/vmdata/vm-200-disk-0 3.09M 574G 88K -
virtualizing/vmdata/vm-200-disk-1 462G 964G 72.5G -
virtualizing/vmdata/vm-201-disk-0 3.11M 574G 108K -
virtualizing/vmdata/vm-201-disk-1 407G 964G 17.2G -
virtualizing/vmdata/vm-202-disk-0 3.07M 574G 76K -
virtualizing/vmdata/vm-202-disk-1 49.2G 606G 16.7G -
virtualizing/vmdata/vm-203-disk-0 3.11M 574G 116K -
virtualizing/vmdata/vm-203-disk-1 39.6G 606G 7.11G -
So you’re saying to list the relevant four ZFS datasets in there but, instead of as bind-points, as virtual drives (as seen in the “rootfs” line)? Or rather, as “storage backed mount points” from here:
https://pve.proxmox.com/wiki/Linux_Container#_storage_backed_mount_points
Hopefully I’m on the right track!
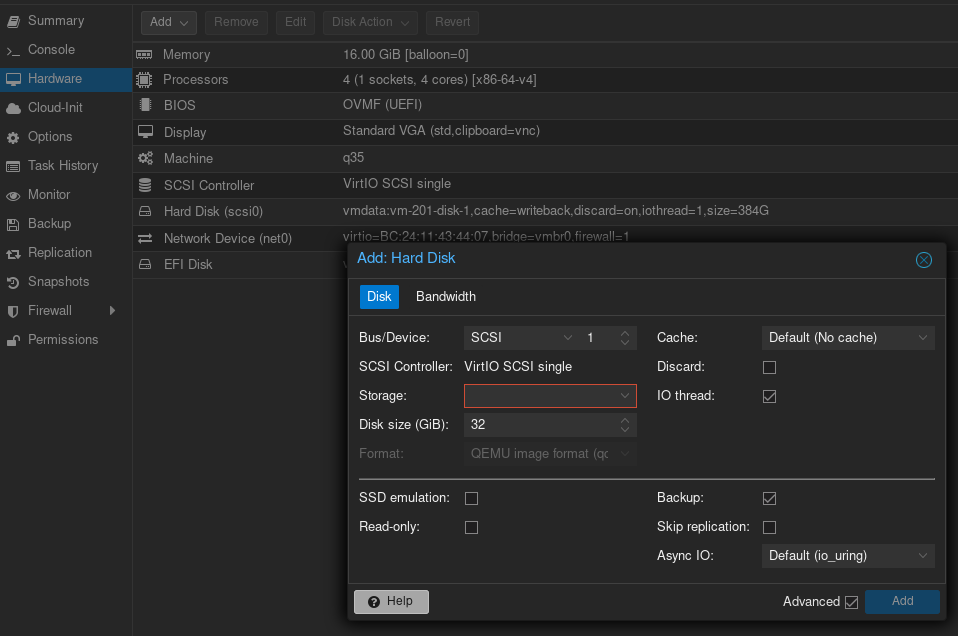

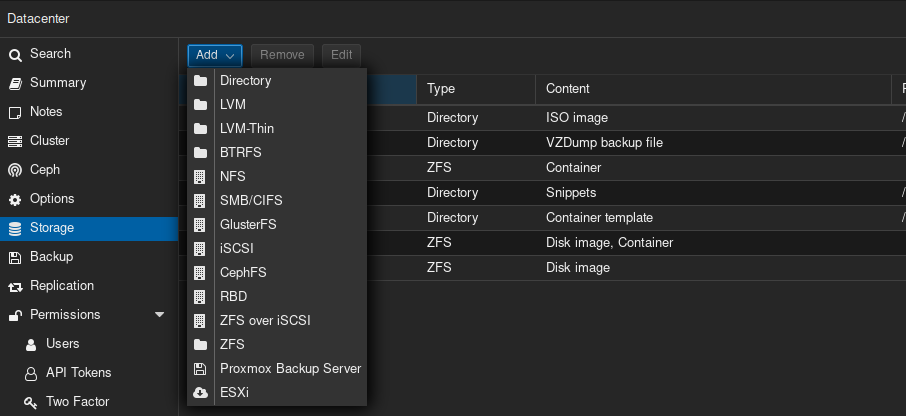
So currently I haven’t re-added any of the data-storing ZFS pools to the Datacenter storage section (wanted to understand what I’m doing before trying anything). Right now my storage.cfg reads as follows (without having added anything):
zfspool: virtualizing pool virtualizing content images,rootdir mountpoint /virtualizing nodes chimaera,executor,lusankya sparse 0 zfspool: ctdata pool virtualizing/ctdata content rootdir mountpoint /virtualizing/ctdata sparse 0 zfspool: vmdata pool virtualizing/vmdata content images mountpoint /virtualizing/vmdata sparse 0 dir: ISOs path /virtualizing/ISOs content iso prune-backups keep-all=1 shared 0 dir: templates path /virtualizing/templates content vztmpl prune-backups keep-all=1 shared 0 dir: backup path /virtualizing/backup content backup prune-backups keep-all=1 shared 0 dir: local path /var/lib/vz content snippets prune-backups keep-all=1 shared 0Under my ZFS pools (same on each node), I have the following:
The “holocron” pool is a RAIDZ1 combo of 4x8TB HDDs, “virtualizing” is RAID mirrored 2x2TB SSDs, and “spynet” is a single 4TB SSD (NVR storage).
When you say to “add a fresh disk” - you just mean to add a resource to a CT/VM, right? I trip on the terminology at times, haha. And would it be wise to add the root ZFS pool (such as “holocron”) or to add specific datasets under it (such as "Media or “Documents”)?
I’m intending to create a test dataset under “holocron” to test this all out before I put my real data through any risk, of course.